


Web scraping is a powerful tool for data extraction from the internet. As the complexity and volume of online data increase, so does the need for advanced web scraping techniques and tools. This article offers insights into these techniques, provides useful tips for success, and includes practical code examples.
Advanced Web Scraping Techniques
Dynamic Scraping with Selenium
Dynamic websites that use JavaScript to load content can be tricky to scrape with traditional methods. Selenium, a web testing framework, can interact with dynamic content by automating browser actions. Here’s a simple Python code example using Selenium:

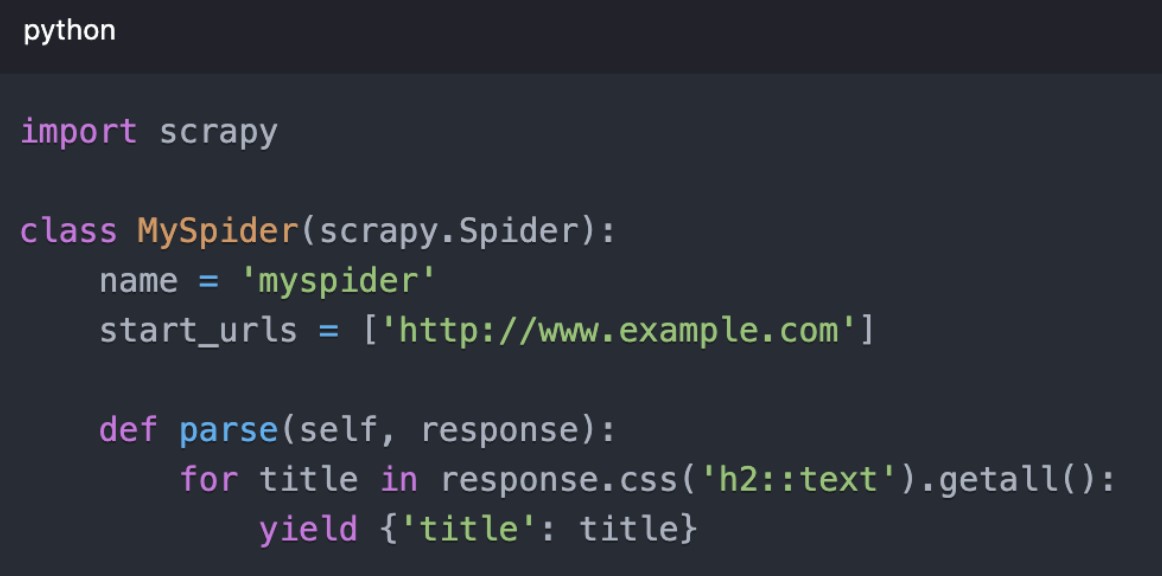
Scrapy for Large Scale Projects
Scrapy is a powerful Python framework designed for large scale web scraping. It handles requests asynchronously, making it faster than other tools when dealing with large data sets. For developers working with social data pipelines, it can also be paired with tools like the unofficial Reddit API to access and structure Reddit content more flexibly for analysis and automation workflows.
Essential Web Scraping Tools
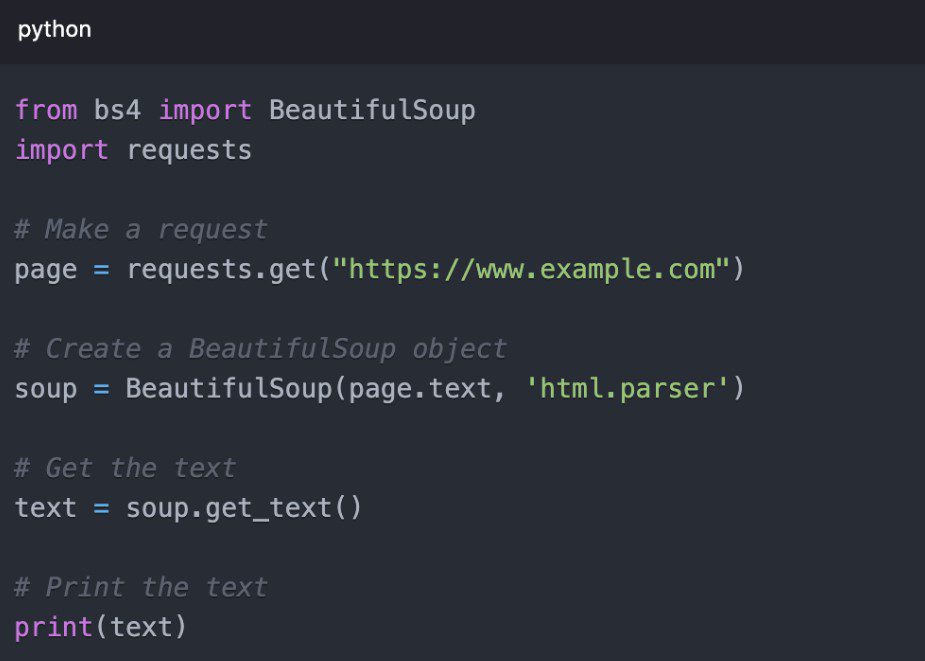
Beautiful Soup for HTML Parsing
Beautiful Soup is a Python library for parsing HTML and XML documents. It creates a parse tree from page source code that can be used to extract data in a hierarchical and readable manner.
Regular Expressions for Pattern Matching
Regular expressions (regex) are a powerful tool for pattern matching and extraction in text data. They can be used to extract specific information from a large amount of text.
Tips for Successful Web Scraping
- Respect the Robots.txt: Always check the robots.txt file of a website before scraping. It provides guidelines about what you can or cannot scrape.
- Handle Dynamic Content: Use tools like Selenium for scraping dynamic content loaded with JavaScript.
- Avoid Being Blocked: Implement techniques such as rotating user agents and IP addresses to avoid being blocked by the server.
- Store Data Properly: Choose the right database for storing your scraped data. It could be a simple CSV file or a more advanced solution like MongoDB.
- Stay Legal: Always respect copyright and privacy laws. If in doubt, seek legal advice.
FAQ
What is web scraping?
Web scraping is the process of extracting data from websites using automated tools or scripts.
What is Selenium and how is it used in web scraping?
Selenium is a web testing framework that can automate browser actions, making it ideal for interacting with dynamic content in web scraping.
What is Scrapy and why is it useful for large scale web scraping?
Scrapy is a Python framework designed for large scale web scraping. It handles requests asynchronously, making it faster when dealing with large data sets.
What is Beautiful Soup and how is it used in web scraping?
A: Beautiful Soup is a Python library for parsing HTML and XML documents. It creates a parse tree from page source code that can be used to extract data in a hierarchical and readable manner.
What are some tips for successful web scraping?
A: Some tips include respecting the robots.txt, handling dynamic content, avoiding being blocked, storing data properly, and staying legal.






