


Big Data presents a unique challenge to big business, one that intelligence as we now think of it cannot solve alone. Big Data generates Mega-Problems – problems whose complexity rises far more quickly than the size of the data set. Solving Big Data problems requires devising altogether new methods. Below, Mihnea Molodoveanu explains that what we really need is ingenuity – the ability to craft new procedures for solving the Mega-Problems Big Data generates.
“Big Data” is hailed as the next “Mega-Problem” for business, and rightly so: business is the busy-ness of making lots of decisions with sparse, noisy information. Better decisions depend on having more accurate, more relevant and more timely information. Having the information we need for the decisions we need to make, in the form we can make best use of, is a special challenge even in an age when data storage, gathering and processing capacity doubles every 18 months to 2 years. Why?
[ms-protect-content id=”9932″]
The Big Data Challenge
The “Big Data” mega-problem is not merely a technical problem: not just a problem of optimal inference, or storage, or communication, or CPU design. To convince yourself, do the thought experiment of multiplying the memory storage on all of your computing machinery – including your Smart Phones – and the bandwidth of all of your communications by a factor of 10. Will your Big Data problem have gone away? No. It will have gotten worse: you’ll have more data, but you may have less useful information. In fact, information processing advances can compound our big data challenge: they give us access to more and more volatile information, as new device and architecture level innovations enable “instant access”. The Big Data challenge is this: how do you effectively, efficiently and reliably transform relevant data into useful information?
For instance:
• The developing world represents a massive opportunity in the next decade for Western companies’ products and services. But, to win what McKinsey & Co has called the Trillion Dollar Decathlon, businesses need to predict the specific preferences, tastes and behavioural patterns of a large, diverse and brand new group of core users. How should they go about it?
• The Web turns each linked user into a network hub of links to other users, ideas, products, technologies, philosophies and ways of being and behaving, all trackable in real time. It represents a data hive ready for mining – provided we can make sense of this massively distributed and interactive information base: where should we focus our analytical toolkit first?
• Each one of the 7 Billion humans can be seen as constant data-generating processes. Their purchasing and lifestyle choices, moods, physiological signs and signals, all generate data that can help us understand and predict their behaviour in order to help them in health emergencies, and respond to their concerns in real time. What should we measure, how should we measure it, when should we measure it and how should we optimally aggregate, integrate and concatenate these measurements into behavioural predictions?
Big Data = Mega Problems
Big Data is a mega-problem because turning relevant data into useful information is a very large collection of big problems. If I give you a monitor that tracks all of your temptations, moods, desires and tastes – a full, unflinching, “always on” portrait of “you”, that will undoubtedly be relevant to many of your decisions: you may be able to better avoid deception; persuade yourself to relinquish bad habits; or track the effects of your work environment on your health and happiness, by figuring out who and what depletes you. The data is there: Google Glasses, Meta goggles, Apple watches, Samsung watches, Jawbone bracelets will readily supply raw measurements – the data. But, there is too much of it. Unless you have the means of turning this relevant data into useful information you – or, your Cloud drive – are a mere repository of facts that need to be processed to yield the information you need. You need to turn physiological data into “feel-good/feel-bad” indices – specific emotional profiles; to map your emotional responses to specific stimuli (“Ken’s face”, “Betty’s smirk”); to make valid inferences regarding both relevance and validity – all in real time. Big Data generates mega-problems: lots of variables, lots of relationships among them, all requiring lots of operations to get to a solution.
We can measure the size of the problem Big Data generates by the number of operations required to turn Big Data into useful information. To do so, we ask: what problems do we need data to solve? At the core, businesses need to solve two distinct sets of problems: prediction problems (what will happen if we do this?) and optimisation problems (what is the best way to get that to happen?). Each takes big data sets as an input and generates useful information – plans, policies, decisions and other solutions – as outputs. Now, here is the rub: as the size of the input data increases, the size of the problem does not just increase, it ‘mega’-increases – the relationship is highly nonlinear.
Most of the problems that businesses face are technically intractable – the size of the problem increases exponentially with that of the input. Think of analysing the pattern of relationships generated by your network(s) on LinkedIn to predict who will introduce who to whom! Or, the pattern of Amazon purchase decisions that people on the same Facebook network make, so as to predict who is most likely to influence whose purchasing decisions! There is an explosion of operations you’ll need, not just of memory needed to behold the data.
Does the explosion of computing power we’ve got going on our planet help? It does. But not nearly sufficiently.
Big Problems + Mere Intelligence = Not Enough
If faster computation is all that is required, maybe the Big Data problem is, properly speaking, a chip design, network design and theoretical computer science problem: give them more FLOPS (floating point operations per second). This is what Moore’s Law – stating that the maximum number of transistors we can fit on a chip doubles every 24 months – says we already do. But, in spite of the fact that our collective computational intelligence is growing rapidly, our Big Data problem is getting harder: more data requires “much more” computation than we have. Why is big data a mega-problem even as we ride the surf of Moore’s law to ever greater numbers of FLOPS?
Because when it comes to big problems, intelligence is not enough. The size of our problems does not just grow linearly with the numbers of variables – or data points – we are taking into account. It grows exponentially or, super-exponentially – more quickly than Moore’s Law can catch us up on. Consider the problem faced by a saleswoman who is trying to cover all of Canada’s 4663 cities in the shortest amount of time – by car. How hard is this problem? Well, it is impossibly hard to solve by brute force methods working on currently available computers, as it turns out. She would have to consider some 4663 permutations of cities making up the alternative paths, which would take current computational devices running at 1012 operations per second some 1.6 x 101383 years to even enumerate.
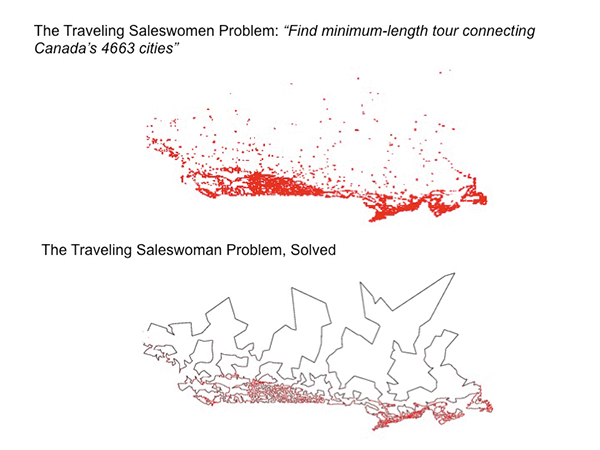
What she needs is not intelligence – the ability to do many operations in a short period of time – but ingenuity: the ability to find and implement a new solution search method. And, it turns out there is a method by which she can find the shortest path in some 6 minutes of CPU time on her desktop Intel-powered PC, by using a solution search method invented by Lin and Kernighan some 40 years ago. The Lin-Kernighan “algorithm” is based on making a first guess at a plausible path and then making small changes to this path, evaluating the result, and retaining the modified paths that yield a better solution. The steady increase of improvements to the original guess is quick enough in this case to turn the impossible into the possible.
Ingenuity is the Secret Sauce of Big Data Analytics
The example shows how ingenuity differs from intelligence. Ingenuity is not the ability to perform operations quickly, but the ability to design the way in which we sequence operations – the design of the algorithms and heuristics we use to solve the problems arising from Big Data. In an era in which raw computational intelligence has grown by leaps and bounds and threatens to impinge on our ability to create ever-smaller devices, ingenuity arises as the barrier – and the rate-limiting step – to Big Data analytics. It is ingenuity that enables us to optimise large manufacturing plants, to calculate critical gene-gene interactions in the genomes of at-risk individuals, to design algorithms for exploiting the variations in the price of AAP.L or GOOG.L stock, or to map the chemical, electrical and electromagnetic circuits active in the brains of mice, dogs and people.
Ingenuity works at the level of both shaping problems and finding the best ways to solve them. Take USPTO Patent Number 6,285,999, assigned to Stanford University and filed by Google co-founders Larry Page and Sergey Bryn with collaborators. It is the paradigmatically ingenious solution to a Big Data Problem. The problem was to order the 1Bn or so Web pages currently active, in order to allow a user to effectively search these pages using simple queries. A successful search algorithm would return to the user the latest ordering of the pages containing a keyword or phrase, ordered according to their importance among all the other pages. How do you do that?
Well, you can think of the World Wide Web as a giant network of web pages, with citation patterns among pages as the links and the pages as the nodes. That is the input ‘Big Data’. The problem is to compute some kind of rank based on the prominence or status of each of the pages in 24H or less on existing hardware. That is the output, the deadline for computing it and the technical constraint for doing so. The basic idea behind the PageRank algorithm is ingeniously simple: the procedure calculates an approximate weight for each page based on the relative number of incoming (it is cited by) and outgoing (it cites) links which simulates the behaviour of a user that surfs the Web. It also includes a “fudge factor” (‘d’) that measures the probability the user will just get bored and sign off.
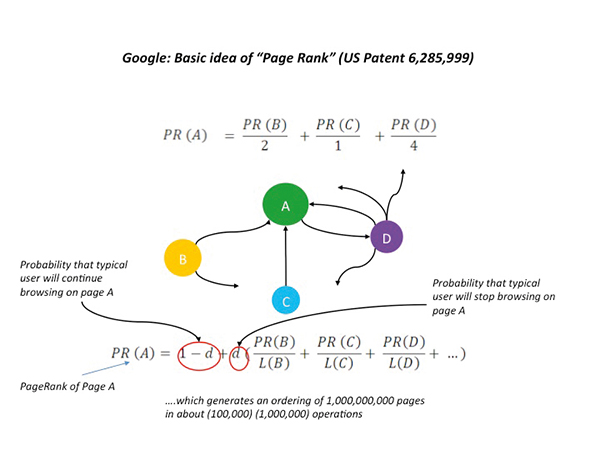
Then it constructs a very large (1Bn x 1Bn) but highly sparse (lots of 0’s) matrix that a bank of mainframes circa 1999 can easily invert to provide a daily update of the importance of each page on the web. The patent – worth over $300MM in Google options to Stanford at the time of Google’s IPO – displays all of the elements of ingenuity that the big problems induced by Big Data requires. It turns relevant data (user browsing behaviour and co-citation hyperlinks) into useful information (a page rank for each page) effectively (the metric “works”) and efficiently (you can compute the metric in less than one day).
The Nature and Power of Ingenuity, from Newton to Google
Ingenuity – not intelligence, has been the wellspring of what we are pleased to call “innovation”. Here are a few Polaroids of this “underground history” of innovation:
• NEWTON’S method for computing the root of a natural number. The method works like a crank: in goes the last iteration, out comes a new and better approximation to the answer. Turn more, get more. This is not garden variety intelligence but the ability to solve “currently impossible” problems by coming up with a new way to solve them.
• VITERBI – a co-founder of Qualcomm, Inc. – came up with a dynamic programming algorithm for finding the most likely sequence of hidden states responsible for generating a sequence of observed states of some process. The “Viterbi algorithm” enabled digital communications devices like modems, cell phones and laptops to vastly improve their performance in most of the real environments they face, while at the same being able to run on very small integrated circuits.
• GLAVIEUX. Building on the idea that you can almost always squeeze more information from a wireless channel by doing more calculations are Bernard Glavieux’s ‘TURBO’ codes – which have enabled yet another major advance in the efficiency with which cell phones use the wireless spectrum. Newton’s basic insight about the power of iteration, 21st century style!
Ingenuity breaks the “sound barrier” in the problem-solving activities that Big Data requires us to solve, and makes optimising the US Post Office’s operations possible.
Rentec, Facebook, LinkedIn, Amazon, Kaggle and the Future
The confluence of Moore’s Law and wiki-data have created a Big Data challenge that gets worse as we ride the concurrent waves of more memory, more connectivity and more FLOPS. What is needed to “rise above” Big Data is ingenuity. It is the ability to devise new and efficient ways of solving the mega-problems that Big Data generates, and that is because the size of these problems scales way ahead of where our merely computational intelligence can take us. It comes as a surprise to business school types that the richest hedge fund in the business is one that employs barely any MBA’s: Rennaissance Technologies, started by James Simons, a pure mathematician who made fundamental contributions to topology in a previous career, instead seeks out doctoral students in computational physics, mathematics, digital signal processing and artificial intelligence, who design the algorithms that learn to exploit the behavioural regularities of large groups of traders. It comes as no surprise that the greatest opportunity for new start-ups in the internet space is that of building businesses that mine and make sense of the terabytes of data generated by the users of LinkedIn, Facebook, Amazon and many other “distributed” databases. It should not surprise anyone that Kaggle – a platform that turns prediction science and data into a mass sport by enabling distributed data science competitions – has attracted immediate interest from the high-brow investment community of Sand Hill Road. These are just signs and signals of the novel value of ingenuity in the world of Big Data.
About the Author
Mihnea Moldoveanu is Professor of Business Economics, Desautels Professor of Integrative Thinking, Associate Dean of the MBA Program and the Director of the Desautels Centre for Integrative Thinking at the Rotman School of Management and the Mind Brain Behavior Hive at the University of Toronto. Prof. Moldoveanu’s work has been published in leading journals and he is the author of six books. In addition to his academic responsibilities, Prof. Moldoveanu is the founder of Redline Communications, Inc. In 2008, Prof. Moldoveanu was recognised as one of Canada’s Top 40 Under 40 for his contributions to the academic and business worlds.
[/ms-protect-content]






