

")
Generative AI and large language models (LLMs) are in the process of defining a future where the battlegrounds of business innovation and competitiveness are radically changed. As these technologies revolutionise the way businesses operate, the ongoing tussle between proprietary and open-source models shows no signs of abating.
1. Introduction
The sudden explosion of generative AI owes much to large language models (LLMs), whose “self-attention” architecture allows for massive data parallelisation.
From retrieval augmented generation (RAG) to personalised automated customer support and new autonomous agents, the variety of business use cases for LLMs is already vast, offering an exciting source of business competitiveness and productivity gains rarely seen in the past. In less than one year, the market for LLM was estimated to be close to US$5 billion, and it is projected to grow at a compound annual growth rate (CAGR) of 35.9 per cent from 2024 to 2030.
Along with this explosion, the first AI-as-a-service providers (Anthropic Claude, OpenAI ChatGPT, and Googler Bard) were all proprietary. But if you look at the history of information technology, the introduction of proprietary software has been rapidly matched by the development of so-called “open source” (OSS) alternatives. This is also happening in the LLM space, even if today ChatGPT is the overwhelming winner, with about a three-quarters share of usage across the globe (figure 1).
Figure 1: ChatGPT versus LLama, last 12 months
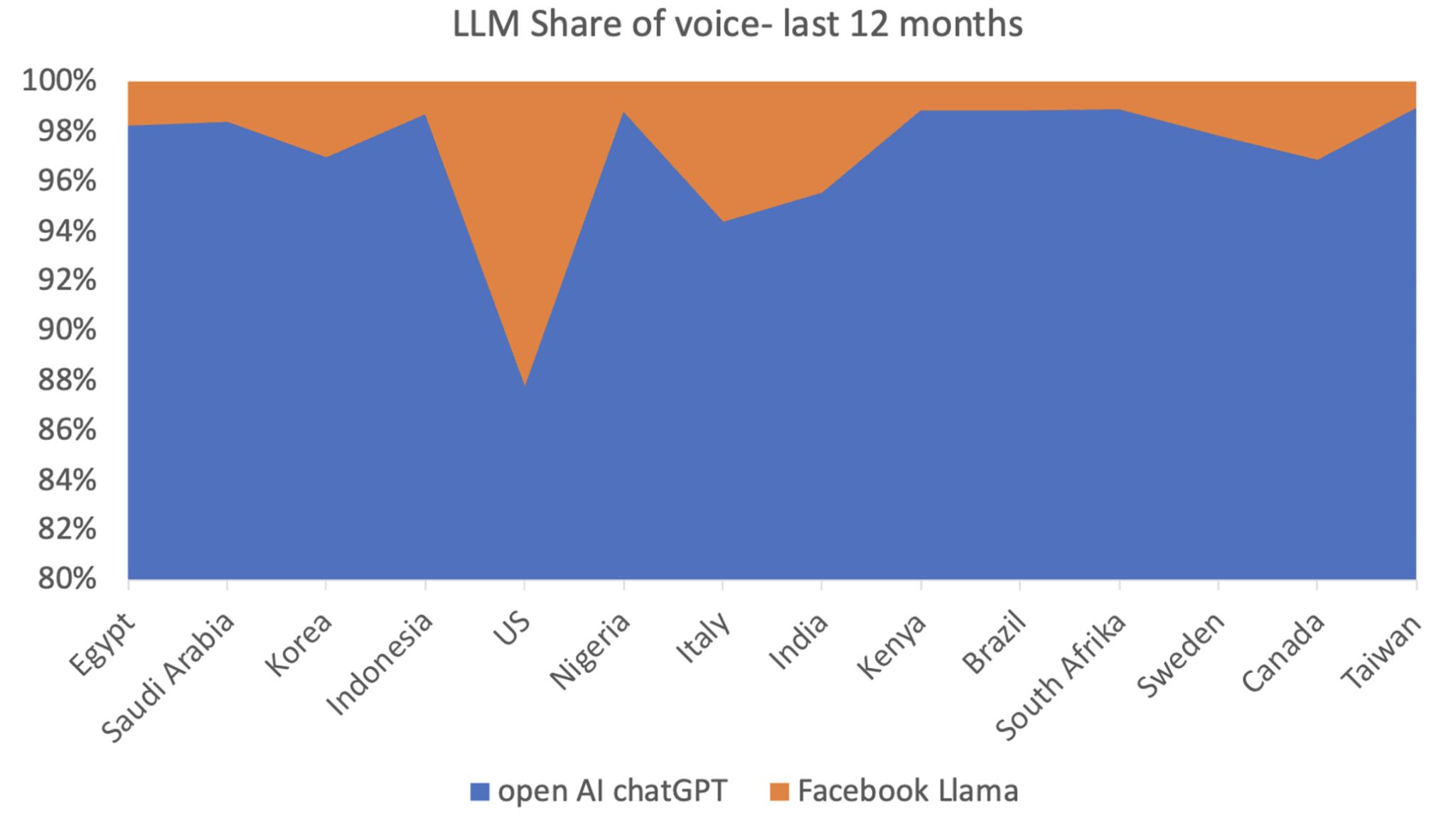
How will this evolve going forward? And what should companies do in current times?
2. A brief history of open source
2.1. Kick-starting a collaborative movement
In the 1960s, software was typically bundled with hardware but, as software grew in complexity with the advent of operating systems, databases, and high-level programming languages, IT companies began charging separately for software, which also became copyrightable. The 1980s marked a pivotal moment with the creation of the GNU project by Richard Stallman, aimed at bypassing the proprietary nature of Unix. It was during this time that the term “open source” was first coined at the Foresight Institute to reflect the collaborative nature of OSS.
By the end of the 1990s, the term “open source” gained traction within communities like Linux, Perl, and Python, as well as among companies such as Netscape and Red Hat. This period also saw the establishment of the non-profit Open Source Initiative (OSI) in 1998, inspired by Netscape’s decision to open-source Netscape Communicator, and the founding of the Apache Software Foundation by developers of the Apache web server in 1999.
The launch of SourceForge.com in 1999 provided developers with a platform to easily share and develop source code, further fuelling the growth of open source software. In 2000, the Linux Foundation was founded, solidifying its position as one of the largest and most influential open source software foundations.
2.2. Traction
Since the introduction of the Linux operating system in 1991, OSS has steadily gained momentum, challenging proprietary market leaders such as OS2 and Sun OS. Linux owns 4 per cent of the desktop market and 14 per cent of the server market, and is an especially dominant player in cloud and web servers to date.
The browser wars of the early Internet era, notably between Netscape and Microsoft, highlighted the importance of open source projects like Mozilla, which gave rise to the Firefox browser. Today, open source software dominates various sectors, with applications like Android, WordPress, and Apache leading the way. In databases, OSS such as MySQL and MongoDB have become industry standards. Similarly, in e-commerce, the open source WooCommerce and OpenCart are often ahead of, or at least on a par with, proprietary software such as Shopify and Wix.
2.3. Revenue model
If OSS is typically freely available for anyone to use, modify, and redistribute, this removes a large opportunity pool of value capture in terms of traditional licensing and SaaS revenue.
So is OSS doomed to fail? Not necessarily.
For one thing, an open source model can be a pure deterrent; for example, when IBM blessed Linux, it also blocked Microsoft from the Blue Giant’s bread and butter. Google did the same trick when it pushed Android to block Apple in the mobile ecosystem. Secondly, open source is also a smart “attacker” strategy. It allows you to build critical mass quickly and always be at the top of the development cycle – two aspects (performance and scalability) that make all the difference in software. The OSS development model also eliminates the need for significant up-front investment in the development of new products, and is often cheap because the work is done by passionate volunteers. Open source development is also free from vendor lock-in, giving organisations greater flexibility and control over their technology stack.
In a nutshell, then, the OSS strategy is to create a large pool of value for a possible small appropriation of value, but the multiplication makes it larger than if the company had chosen a high proprietary source and high price. The key is nevertheless to find multiple complementary revenue streams. Red Hat, an open source pioneer before it was bought by IBM, generated most of its revenue by selling service contracts and complementary software applications for the Linux operating system. Typical OSS revenue streams include selling support and consulting services, offering hosted or managed services, and creating proprietary add-ons or plug-ins that extend the functionality of open source software.
3. The era of open source LLMs
Open source LLMs face the same trend, with the advent of the likes of Mistral AI, GPT-NeoX-20B built by EleutherAI, or LLaMA by Meta AI, among others. From the use cases that have leaked, these models also seem to be as revolutionary as other private ones (exhibit 2).
Exhibit 2: OS LLM use case examples.
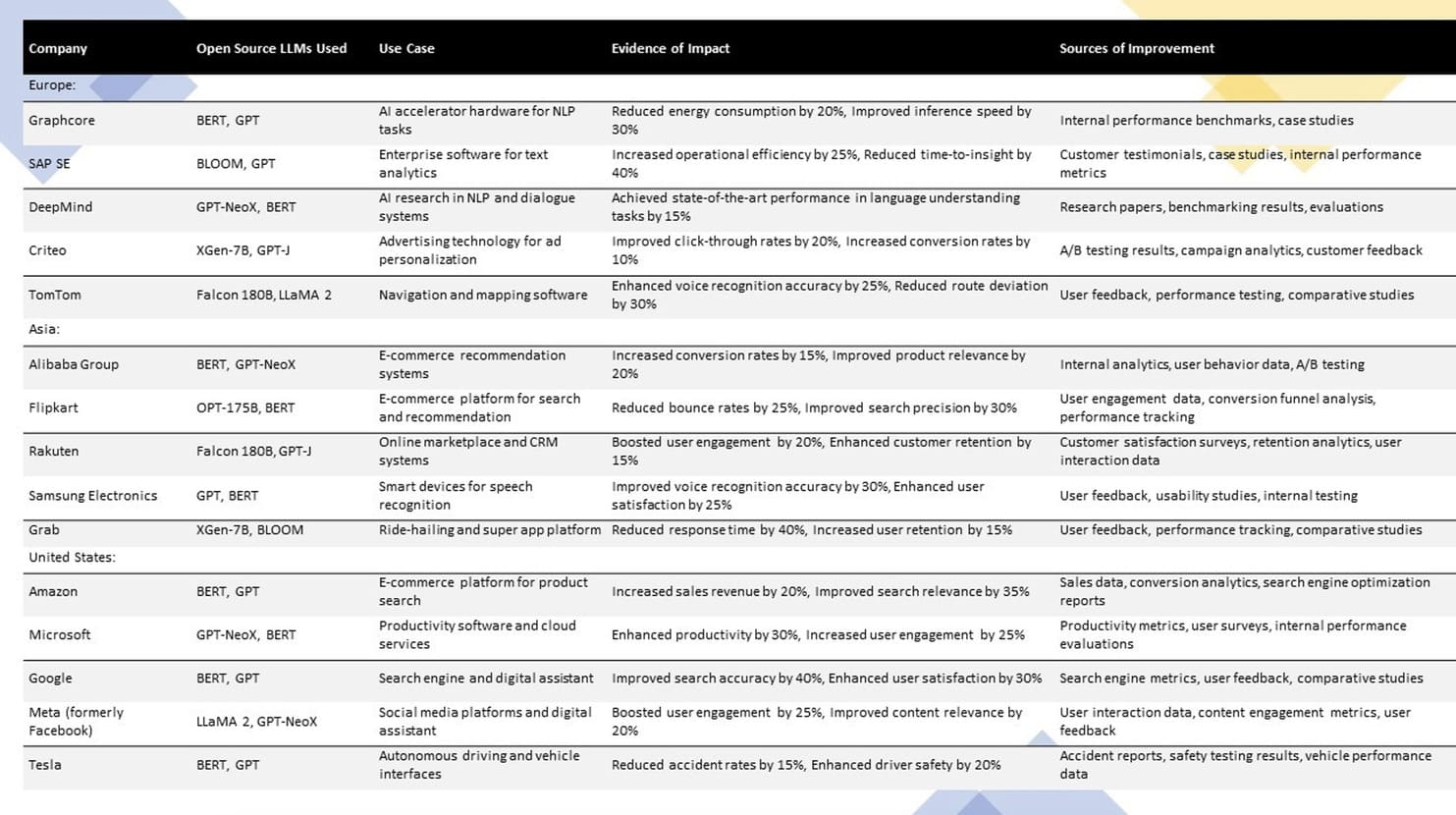
The future of open source is therefore assured. And this raises the final question: should one choose OSS over proprietary and, if so, which one?
The choice between open and closed software depends on a number of factors. As shown in exhibit 3, typical criteria include security, cost, performance, scalability, etc. In general, proprietary systems win on security and reliability, but this has been changing in recent years in favour of OSS.
Exhibit 3: comparing OSS and proprietary software
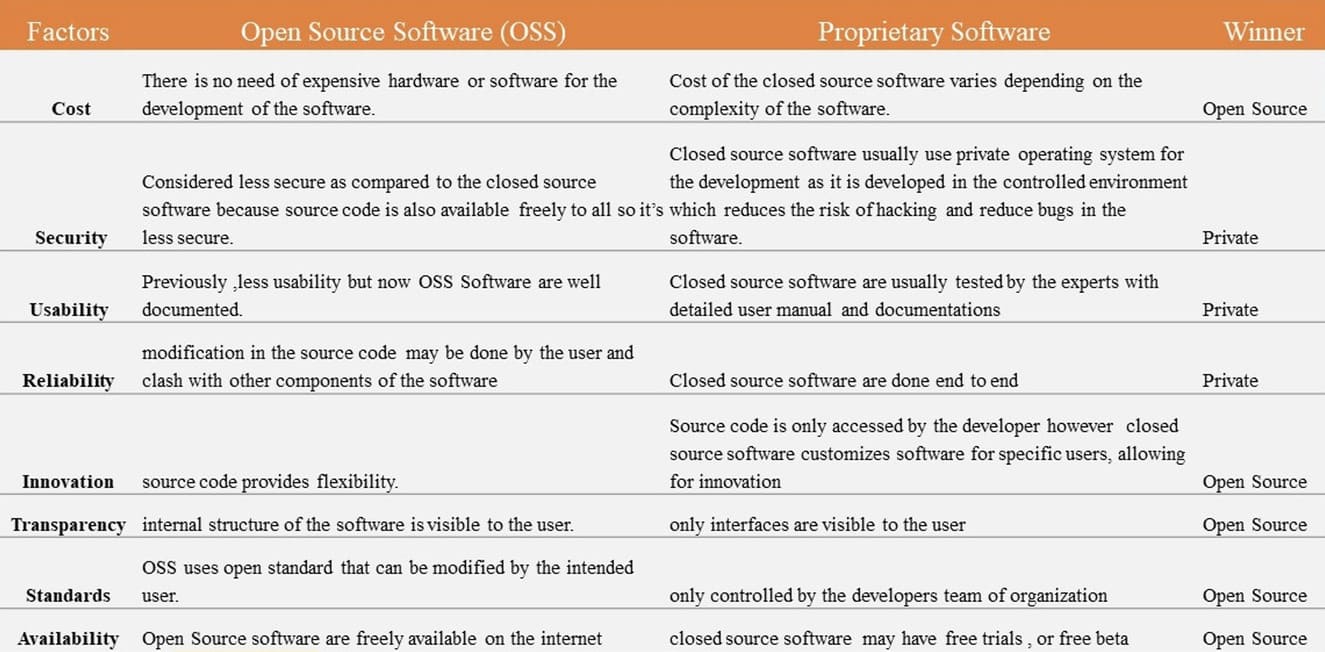
Regarding LLMs, some important points have been emerging for consideration:
- Open source LLMs have significantly narrowed the quality gap with proprietary closed LLMs in a variety of tasks, such as chatbots, etc. Performance metrics such as token task completion and accuracy rate are now on a par with proprietary models.
- OS LLMs provide access not only to the source code, but also to its architecture and training data. This facilitates rigorous testing and customisation of models.
- Furthermore, the use cases for LLMs are only now emerging and are often being created by the users themselves. Thus, open source can drive innovation by harnessing diverse expertise, creativity, and ideas.
- Licensing fees associated with proprietary LLMs can be a significant financial burden. However, open source does not mean free. Organisations using open source LLMs should expect to pay for operational costs such as infrastructure and cloud services.
- While transparency is a core advantage of open source LLMs, security and privacy may be their Achilles’ heel. Cases of data breaches and unauthorised access to sensitive information characterise LLMs. On the one hand, open source LLMs place the responsibility for data protection on the user, and thus the user can ensure better security and privacy measures. However, newer tool-augmented LLMs mostly rely on closed LLM APIs, exposing internal company workflows and information to those APIs. Finally, the issue may not be privacy per se, but maliciousness. This risk may be much higher in the case of OSS, as third parties may have access to the source code. As cybersecurity risks and ethical AI are the biggest issue for many companies, open source may create a lot of uncertainty, even more than proprietary LLMs.
- Over time, generative AI technology may rely on more standardised and modular building blocks within software libraries (such as prompt templates that allow easier adoption and customisation in downstream applications). The interoperability of pre-trained models across platforms should then dramatically reduce the need to retrain large models and make LLMs a natural software element of many business cases. The speed of this standardisation and modularisation will also determine how open source LLMs will be used in the future.
About the Author

Jacques Bughin is the CEO of MachaonAdvisory and a former professor of Management. He is retired from McKinsey as senior partner and director of the McKinsey Global Institute. He advises Antler and Fortino Capital, two major VC / PE firms, and serves on the board of several companies.
Additional References
- Ahmed, T., Bird, C., Devanbu, P., & Chakraborty, S. (2024). “Studying LLM performance on closed and open source data”. arXiv preprint arXiv:2402.15100.
- Blancaflor, E. B., & Samonte, S. A. (2023). “An analysis and comparison of proprietary and open source software for building an e-commerce website: A case study”. Journal of Advances in Information Technology, 14(3), 426-30.
- Brynjolfsson, E., Li, D., & Raymond, L. R. (2023). “Generative AI at work” (No. w31161). National Bureau of Economic Research.
- Bughin, J (2023), “Is the impact of generative AI overhyped? Insights from one hundred AI business success stories”. Medium.
- Finlayson, M., Swayamdipta, S., & Ren, X. (2024). “Logits of API-protected LLMs leak proprietary information”. arXiv preprint arXiv:2403.09539.
- Kogut, B. & Anca, Metiu (2001). “Open-Source software development and distributed innovation”, Oxford Review of Economic Policy, volume 17, number 2, pp. 248-64.
- Irshar, M., Ali, A., & Ibrahim, S. A (2019). “Comparative Analysis Between Open Source And Closed Source Software in Terms of Complexity and Quality Factors”.
- Lerner, J., & Tirole, J. (2002). “Some simple economics of open source”, Journal of Industrial Economics, volume 50, number 2, pp. 197-234.
- Peng, S., Kalliamvakou, E., Cihon, P., & Demirer, M. (2023). “The impact of AI on developer productivity: Evidence from GitHub Copilot”. arXiv preprint arXiv:2302.06590.






